파이썬으로 크롤러 만들기
어떤 웹사이트의 데이터를 DB화(DB, Excel, JSON, 기타 어떤 형태건 다시 사용할 때 정렬, 필터 등이 편리한 형태로 저장하는 것을 DB화로 표현했습니다) 하고싶을 때 크롤러를 만들어 사용하게 됩니다. 사이트에서 필요한 정보를 엑셀로 다운받는 기능을 제공한다면 크롤러를 만들 필요가 줄어듭니다. 이런 기능을 제공하지 않는 사이트는 사람이 직접 여러 링크를 클릭해가며 정보를 모아야 하는데 페이지가 많다면 수집과정이 귀찮기도 하고 실수가 발생할 수 있습니다. 크롤러는 사람이 수집하는 과정을 그대로 따라하지만 지치지 않고 빠르며 실수하지 않습니다.
HTML 이해
엑셀은 xls파일, 워드는 doc파일이 있는 것처럼 웹은 html파일로 표현됩니다. 우리가 어떤 사이트의 특정 url 페이지에 접근하는 것은 그 url에 해당하는 html파일을 다운로드하여 보는 것과 같습니다.
사람은 웹페이지에 표현된 요소들이 상품명을 의미하는지 가격인지 섬네일 이미지인지 알아보는 능력이 있지만 기계는 그렇지 않습니다. 크롤러를 작동시키려면 페이지에서 어떤 요소를 수집할 것인지 정확히 표현해야 합니다. 그래서 크롤러를 만들려면 html을 어느정도 이해해야 합니다.
태그, 엘리먼트
<html></html>html은 여러가지 태그를 조합하여 사용합니다. 위 예제에서 <html>은 여는 태그 </html>은 닫는 태그입니다.
태그는 요소(element)라는 의미로 엘리먼트라고 부르기도 합니다.
태그 중첩
<html><body></body></html>html은 여러 태그를 중첩하여 사용할 수 있습니다. 위 예제에서 body태그는 html태그 안에 들어가있습니다. 이 때 body는 html의 자식 태그 html은 body의 부모 태그라고 부릅니다.
<html>
<body></body>
</html>위 예제는 그 이전의 예제와 동일한 의미의 html 코드입니다. Python에서 어떤 띄어쓰기는 실행결과에 영향을 주지 않는 것과 마찬가지입니다.
<html>
<body>
<p>대한민국은 민주공화국이다. 대한민국의 주권은 국민에게 있고, 모든 권력은 국민으로부터 나온다.</p>
<p>대한민국의 국민이 되는 요건은 법률로 정한다. 국가는 법률이 정하는 바에 의하여 재외국민을 보호할 의무를 진다.</p>
</body>
</html>위 예제에서 p 태그는 텍스트를 포함하고 있습니다. p는 paragraph의 약자로 단락을 표현할 때 사용합니다. 위 html을 파일로 저장하여 크롬같은 브라우저에서 열면 아래와 같이 표현됩니다.

어떤 태그는 화면에 표현됩니다. 하지만 html, body 태그처럼 화면에 표현되지 않는 것도 있습니다.
위 예제에서 p 태그에게 html 태그는 조상이고 html 태그에게 p 태그는 자손이라 부릅니다. 바로 부모나 자식 관계가 아니고 중간에 body 태그가 있기 때문입니다. body와 p를 부모 자식 관계라고 정의 할 수 있지만 조상 자손 관계라고 정의 할 수도 있습니다. 조상, 자손이 더 넓은 개념이기 때문입니다.
Self-Closing 태그
<html>
<body>
<p>
<img src="https://9cells.com/storage/uploads/lN/YJ/lNYJsR2vcm4dt6AI00NgPtTOy2x6pU1d7YML9aeu.jpg">
대한민국은 민주공화국이다.<br/>대한민국의 주권은 국민에게 있고,
모든 권력은 국민으로부터 나온다.
</p>
<p>대한민국의 국민이 되는 요건은 법률로 정한다.<br>
국가는 법률이 정하는 바에 의하여
재외국민을 보호할
의무를 진다.</p>
</body>
</html>여기에 <img> <br/> 같은 특이한 태그가 나옵니다. img태그는 이미지를 출력할 때 사용되고 br태그는 줄바꿈을 할 때 사용됩니다. 위 html의 실행결과는 다음과 같습니다.

<img>태그는 url의 이미지를 출력하고 <br>태그가 나타날 때마다 줄바꿈이 된 것을 확인할 수 있습니다. html 코드 상에서 br 태그 없이 줄바꿈을 한 부분은 브라우저로 표현될 때 줄바꿈 되지 않습니다.
img태그와 br태그는 여는 태그와 닫는 태그가 없고 <img/>, <br/>로 사용됩니다. 이렇게 사용하는 태그들을 self-closing 태그라고 부릅니다. <img>...</img>, <br>...</br>(잘못된 사용)처럼 self-closing 태그 사이에 다른 콘텐츠를 넣는 것은 무엇을 표현하려는 것인지 애매합니다. self-closing 태그는 이렇게 자손 태그를 갖지 않는 태그입니다.
<img/>, <br/>대신 간단히 <img>, <br>로 사용해도 됩니다. 마치 여는 태그만 있고 닫는 태그가 없는 것처럼 보이지만 self-closing 태그에 대해 이런 사용을 허용합니다.
속성, attribute, 어트리뷰트
<html>
<body>
<p class="goods">
<img src="https://9cells.com/storage/uploads/lN/YJ/lNYJsR2vcm4dt6AI00NgPtTOy2x6pU1d7YML9aeu.jpg"
width="676" height="406" />
<span class="name"><b>상품명:</b> 핸드폰 거치대</span><br>
<span class="price"><b>가격:</b> 20,000원</span><br>
</p>
<p class="goods">
<img src="" width="" height="" />
<span class="name"><b>상품명:</b> 핸드폰 거치대</span><br>
<span class="price sale"><b>가격:</b> 16,000원</span><br>
</p>
</body>
</html>태그에는 속성을 추가하여 부가정보를 표현합니다. img태그에는 src 속성을 사용하여 어떤 url의 이미지를 보여줄지 정할 수 있습니다.
class 속성에는 해당 엘리먼트가 어떤 종류의 것인지 html 페이지 작성자가 이름을 지정할 수 있습니다.
위 예제에는 goods라는 class의 두 태그가 있습니다. 상품을 표현하려고 붙인 이름입니다. 가격을 표현하는 태그에는 price라는 클래스명이 붙어있습니다. price sale이라고 붙어있는 태그는 price와 sale 두 클래스명을 지정한 것입니다.
스타일, CSS, 선택자, 셀렉터
<html>
<head>
<style>
.goods {
width: 300px;
background-color: yellow;
border: 1px solid black;
padding: 10px;
}
.goods.soldout {
background-color: darkgray;
text-decoration: line-through;
}
.goods span {
display: block;
}
.goods .price.sale {
color: red;
font-size: larger;
}
</style>
</head>
<body>
<p class="goods soldout">
<span class="name"><b>상품명:</b> 핸드폰 거치대</span>
<span class="price sale"><b>가격:</b> 16,000원</span>
</p>
<p class="goods">
<span class="name"><b>상품명:</b> 핸드폰 거치대</span>
<span class="price"><b>가격:</b> 20,000원</span>
</p>
<p class="goods">
<span class="name"><b>상품명:</b> 핸드폰 거치대</span>
<span class="price sale"><b>가격:</b> 16,000원</span>
</p>
</body>
</html>웹페이지를 디자인하려면 CSS라는 언어를 사용합니다. 위 예제에서 html > head > style 태그 안에 쓰여진 코드가 CSS입니다. 이 예제의 파일을 브라우저에서 열면 다음과 같은 결과가 나옵니다.

상품을 표현하는 비슷하면서도 다른 스타일의 박스 세 개가 보입니다. 이러한 스타일이 어떻게 설정됐는지 살펴봅시다.
.goods {
width: 300px;
background-color: yellow;
border: 1px solid black;
padding: 10px;
}CSS는 html 요소를 선택하여 스타일을 지정하는 형태의 언어입니다. .goods는 클래스명이 goods인 엘리먼트들의 스타일을 지정하겠다는 의미입니다. 이때 어떤 엘리먼트를 선택할 것인지 지정한 .goods 부분을 셀렉터(선택자)라고 부릅니다. .goods 요소들의 배경색을 노란색으로, 테두리를 1px 검정 실선으로 지정한 코드입니다.
.goods.soldout {
background-color: darkgray;
text-decoration: line-through;
}.goods.soldout은 class가 goods이면서 soldout인 요소를 선택하는 셀렉터입니다. 여기서는 회색 배경색에 텍스트는 취소선으로 지정했습니다. 실행 결과에서 한 박스만 노란색이 아닌 회색으로 보여지는데 해당 박스의 html은 <p class="goods soldout">... 이런식으로 지정된 것을 볼 수 있습니다.
.goods .price.sale {
color: red;
font-size: larger;
}위 CSS에서 .goods .price.sale 셀렉터에는 중간에 띄어쓰기가 되어있습니다. 이 의미는 .goods 태그의 자손 중 .price.sale 두 클래스명을 한 번에 갖고있는 엘리먼트를 선택한 것입니다. 실행결과에서 <span class="price sale">...</span>의 코드는 빨갛고 좀 더 큰 텍스트로 보여지는 것을 확인할 수 있습니다.
이 셀렉터는 .goods .price.sale 대신에 .price.sale 이렇게만 사용해도 이 html 예제에서 문제가 되지 않습니다. 하지만 html 페이지에 태그가 점점 추가되고 같은 페이지 내에서 다른 디자인으로 상품을 표현할 일이 생길 때 price, sale 클래스명을 다시 사용한다면 .goods로 제한하지 않은 CSS 스타일이 적용될 수 있습니다. 이런 것을 막기 위해 goods 자손에 대해서만 스타일을 지정하도록 제한하여 확장에 유연하게 대처할 수 있습니다. 만약 다른 형태의 상품 스타일이 필요하다면 goods2 같은 이름을 사용할 수 있습니다.
.goods span {
display: block;
}위 코드에는 .goods와 span 사이에 띄어쓰기가 있습니다. 앞서 설명드린 것처럼 이는 .goods의 자손 중 span인 요소를 선택하는 셀렉터입니다. span은 class가 아닙니다. span이 .으로 시작되지 않는 점에 주의해주세요. 이렇게 .으로 시작되지 않는 것은 태그를 선택하는 것입니다. 즉, goods 클래스명의 엘리먼트 자손 중 span 엘리먼트를 선택하라는 의미입니다.
엘리먼트 선택자를 사용하여 html 페이지를 검정색 배경으로 지정하고 싶다면 다음과 같은 코드로 가능합니다.
html {
background-color: black;
}엘리먼트 셀렉터는 태그 이름을 셀렉터에 쓴다는 점을 기억해주세요.
크롤러 구현 시 HTML 읽기
간단히 HTML과 CSS 사용방법을 알아봤습니다. 파이썬으로 크롤러를 만드는데 왜 HTML, CSS를 설명하는지 궁금하실 수 있습니다. 웹 크롤러를 만드는 것은 결국 html 요소들을 선택하고 선택한 요소들의 데이터를 뽑아내는 형태이기 때문입니다. 이 때 CSS 셀렉터를 사용합니다.
크롤링하려는 대상 페이지의 html을 보려면 크롬 브라우저에서 해당 페이지로 이동 후 F12 단축키를 누르면 됩니다.
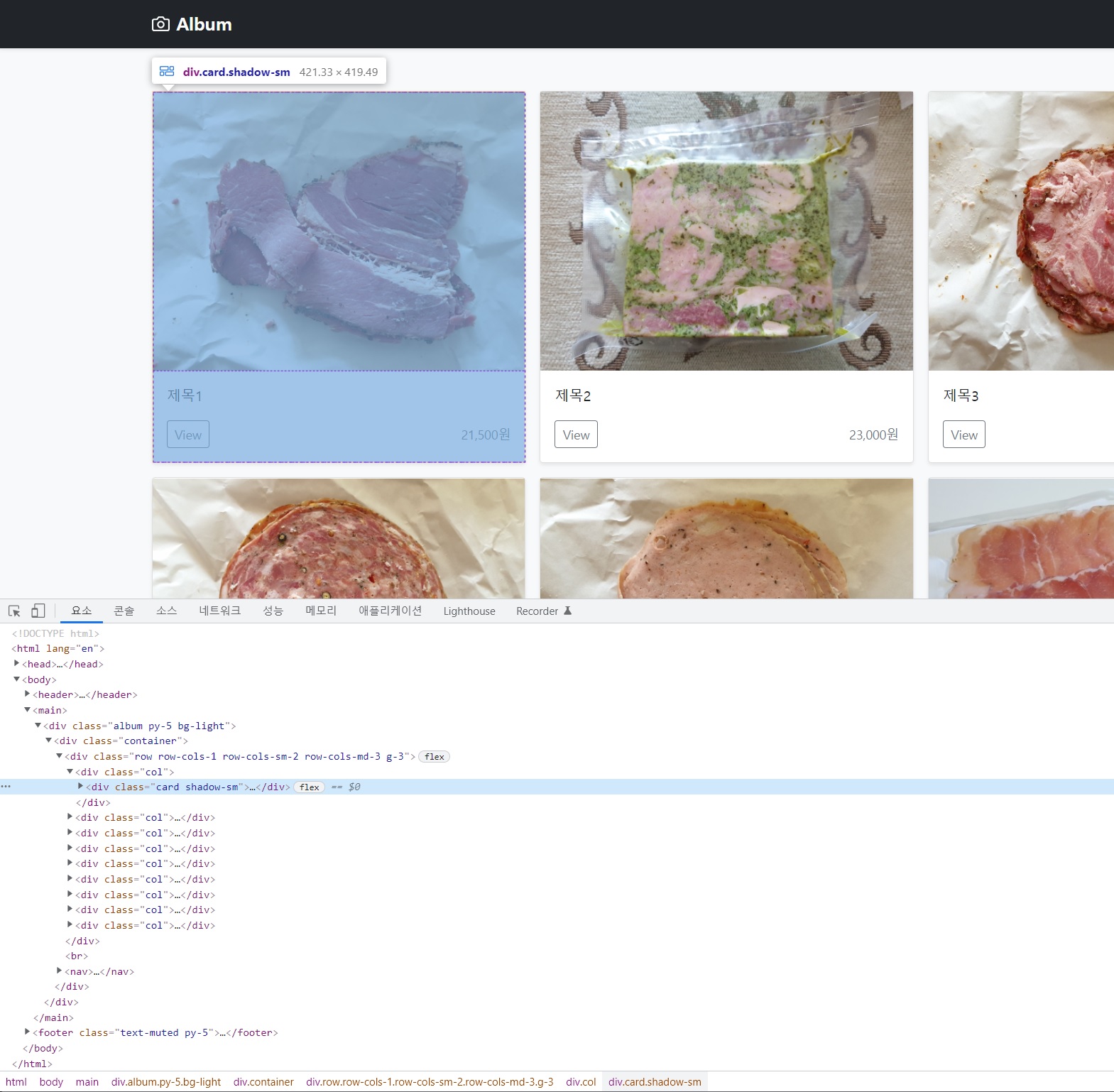
html 코드 상에서 엘리먼트를 클릭하면 브라우저에서 해당 요소가 어떤 것인지 확인할 수 있습니다. 태그 이름과 클래스명을 적절히 사용하여 크롤러 제작 시 해당 요소들을 선택할 수 있습니다.
크롤러
셀레늄 준비
소프트웨어 개발에는 바퀴를 재발명 하지말라는 격언이 있습니다. Python은 다른 사람이 만들어 공개한 코드를 가져다가 사용하는 것을 매우 간단하게 할 수 있습니다. 이렇게 공개된 기능들을 패키지라고 부릅니다.
브라우저 작동을 제어할 수 있는 셀레늄이라는 도구가 있습니다. 이를 파이썬에서 사용할 수 있는 패키지를 설치해봅시다.
- 윈도우 단축키: <Win 키> + R
- 실행창이 뜨면
cmd입력 후 확인 (또는 엔터) - 검정색 콘솔창이 뜨면 다음을 입력:
pip install selenium
셀레늄 파이썬 사용자 메뉴얼은 여기에서 확인할 수 있습니다.
다음으로 셀레늄이 크롬 브라우저를 제어할 수 있도록 크롬 드라이버가 필요합니다. 크롬 드라이버 다운로드 페이지로 이동하여 자신에게 맞는 버전을 다운받습니다. 크롬 브라우저의 버전은 메뉴에서 도움말 > Chrome 정보를 클릭하면 97, 98, 99로 시작하는 버전을 확인할 수 있습니다.
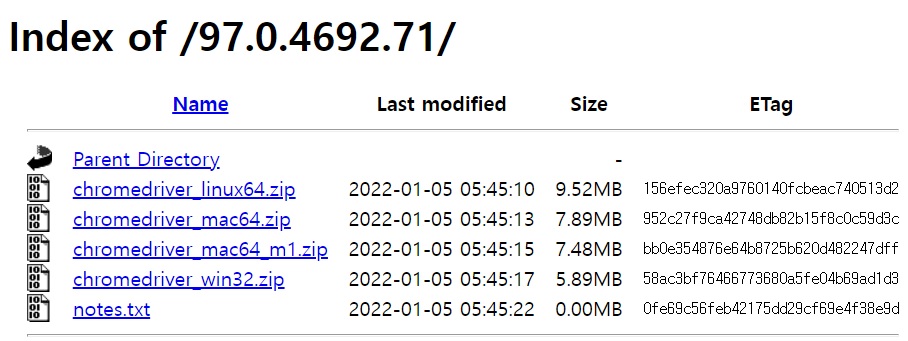
버전을 선택하면 위와 같은 페이지를 볼 수 있습니다. 저는 윈도우 사용자이므로 chromedriver_win32.zip를 다운받았습니다. 맥 사용자는 파일명에 mac이 들어가는 파일 중 자신의 환경에 맞는 압축파일을 다운받으세요. 다운받은 압축파일을 해제하면 chromedriver.exe 같은 파일이 들어있습니다. 이 파일을 복사하여 우리 스터디용 디렉토리(C:\Notepad\sourcecode\python)에 붙여넣습니다.
크롤러 예제
온라인 쇼핑몰의 전체 상품을 크롤링 한다면 보통 다음과 같은 과정이 필요합니다.
- 로그인이 필요하다면 로그인
- 상품 목록 페이지에서 상품 url 수집
- 다음 페이지가 있으면 이동 후 2를 수행
- 수집한 전체 상품 페이지에 접근하여 상세정보 수집
크롤링 예제 코드를 살펴봅시다.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
service = Service(r"C:\Notepad\sourcecode\python\chromedriver.exe")
options = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome(service=service, options=options)
products = []
driver.implicitly_wait(1)
driver.get("<예제 url>")
page = 1
while True:
# smooth scroll 끄기
js = "document.querySelector('html').style.scrollBehavior = 'auto'"
driver.execute_script(js)
# 상품 url 수집
cards = driver.find_elements(By.CSS_SELECTOR, '.card a')
products += [{'url': card.get_attribute('href')} for card in cards]
# 페이지 출력
print(f'{page} 페이지')
page += 1
# 다음 페이지 이동
el_nexts = driver.find_elements(By.CSS_SELECTOR, 'a[rel=next]')
if len(el_nexts) == 0: break
el_nexts[0].click()
for product in products:
# 상세 페이지 이동
driver.get(product['url'])
# 상품명
product_name = driver.find_element(By.CSS_SELECTOR, 'h2').text
product['name'] = product_name
# 가격
s_price = driver.find_element(By.CSS_SELECTOR, '.list-group strong').text
s_price = s_price.replace(',', '')
product['price'] = int(s_price)
# 섬네일 url
product['thumbnail'] = driver \
.find_element(By.CSS_SELECTOR, '.details img') \
.get_attribute('src')
# 상세페이지 html
product['details'] = driver \
.find_element(By.CSS_SELECTOR, '.details') \
.get_attribute('innerHTML') \
.strip()
print(f'{product_name} {s_price}원')
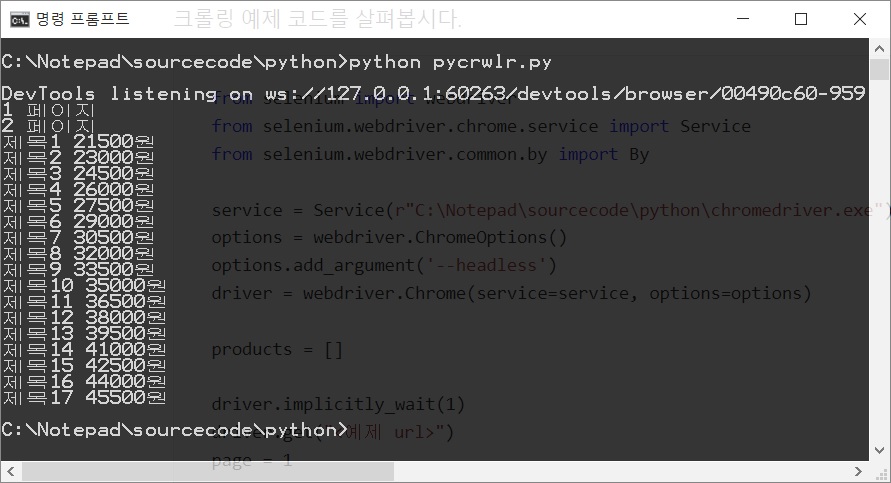
driver.close()이 코드의 실행결과는 이렇습니다.
셀레늄 사용준비
크롤러 예제는 셀레늄을 사용한다고 말씀드렸습니다. Python에서 패키지를 사용하려면 설치한 패키지의 기능들을 import 해줘야 합니다.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By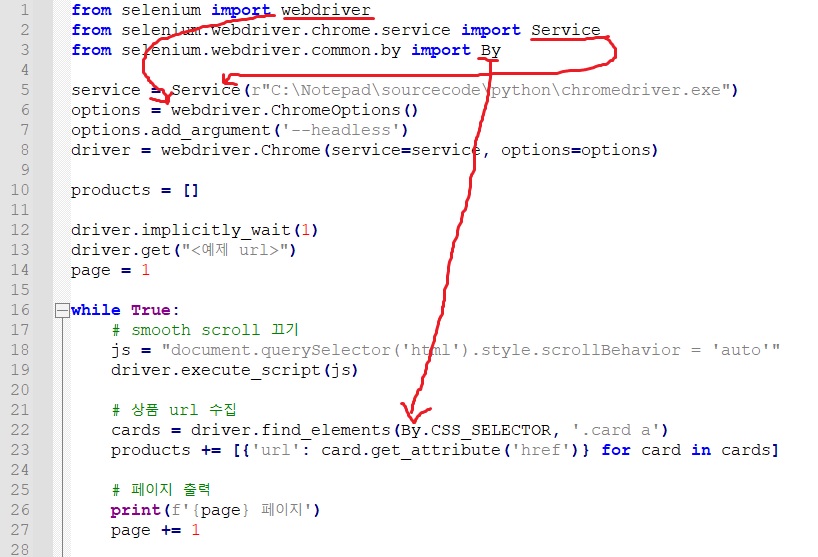
위 이미지 상의 코드에서 import한 것들이 어떻게 쓰이는지 살표보실 수 있습니다.
service = Service(r"C:\Notepad\sourcecode\python\chromedriver.exe")
options = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome(service=service, options=options)import 이후에 이어서 나오는 코드들은 셀레늄을 초기화 하는 코드입니다. 결국 webdriver.Chrome() 을 호출하여 driver를 얻는 것이고 이 호출에 service, options가 사용됩니다.
service는 우리가 다운받아 복붙한 크롬 드라이버의 파일 주소가 들어갑니다.
options에는 --headless 옵션을 추가했습니다. 이 옵션은 크롤러 진행 시에 브라우저를 감추고 크롤링을 진행하게 하는 옵션입니다. 이 라인을 다음 코드처럼 주석처리하면 크롤링 중에 브라우저의 작동을 지켜볼 수 있습니다.
# options.add_argument('--headless')여기서 이런 사용방법은 어떻게 알고 작성했는지 궁금하실 수 있습니다. 파이썬 언어를 배우면서 실행해본 예제들은 풀어야하는 문제가 있고 그 문제를 푸는 전략을 세우고 배운 언어적 요소들을 사용하여 코드를 작성했습니다. 하지만 공부한 내용만 가지고는 셀레늄을 초기화하는 코드를 상상해내기 어렵습니다.
이런 코드는 메뉴얼을 읽어보고 작성하게 됩니다. 외부 패키지를 사용하는 것이므로 해당 패키지를 사용하는 방법은 패키지 제작자가 설명하는 것이 당연합니다. 셀레늄 파이썬 메뉴얼 사이트에 초기화 방법이 자세히 설명되어 있습니다. 예제의 코드도 메뉴얼의 내용을 조합하여 작성한 코드입니다.
배경지식이 없는 외부 패키지 사용에 당황하지 마시라고 적어봅니다.
상품 목록 페이지로 이동
products = []
driver.implicitly_wait(1)
driver.get("<예제 url>")
page = 1
while True:
# smooth scroll 끄기
# 상품 url 수집
# 페이지 출력
# 다음 페이지 이동셀레늄 초기화 후 이어지는 코드는 본격적으로 크롤링을 수행하는 코드입니다.
먼저 빈 products 리스트를 초기화 하는 것을 보실 수 있습니다. 이 예제의 실행이 완료되면 products에 다음과 같은 상품 데이터가 수집되도록 구현하려고 합니다.
# products =
[
{
'url': '/pycrwlr/1',
'name': '제목1',
'price': 21500,
'thumbnail': '/storage/uploads/bD/0K/bD0KV9swV5jZfPpV3GDKOBQor.jpeg',
'details': '<img src="/storage/uploads/bD/0K/bD0KV9swV5jZfPpV3GDKOBQor.jpeg">'
},
{
'url': '/pycrwlr/2',
'name': '제목2',
'price': 23000,
(...생략...)
}
(...더 많은 상품...)
]상품 데이터를 저장하는 dictionary와 이 목록을 저장하는 list입니다. dictionary와 list는 파이썬 스터디에서 공부하신 그것입니다.
driver.implicitly_wait(1)위 코드는 이 코드 이후로 드라이버가 페이지를 이동할 때 페이지가 읽혀지기까지 기다리는 시간으로 1초를 지정한 코드입니다. 페이지 로딩에 더 많은 시간이 필요한 사이트라면 몇 초 더 기다리게 설정하셔야 할 수도 있습니다.
driver.get("<예제 url>")이 driver.get()코드가 실행되면 크롤러는 예제 url로 이동합니다.
while True:
# smooth scroll 끄기
# 상품 url 수집
# 페이지 출력
# 다음 페이지 이동무한루프로 while문을 실행합니다. 코드를 생략했지만 이 while 안에서 상품 목록 페이지를 넘겨가며 전체 상품 url을 수집합니다.
상품목록 수집
바로 위에서 상품목록 페이지를 이동하며 상품의 url을 얻는 while문을 설명했습니다. while문의 내부 코드를 살펴봅시다.
# smooth scroll 끄기
js = "document.querySelector('html').style.scrollBehavior = 'auto'"
driver.execute_script(js)크롤러 개발 중에 경험하게 되는 까다로운 문제 중 한 예입니다. 이 코드는 브라우저에서 작동하는 javascript(js)라는 언어로 document.querySelector('html').style.scrollBehavior = 'auto'를 실행하도록 execute_script()를 호출한 것입니다.
크롤러는 남이 만든 사이트에 의존적이기 때문에 사이트가 어떻게 만들어졌는지에 따라 다양한 문제들을 겪을 수 있습니다. 이런 문제를 이해하고 해결하는 것에는 웹 개발 경험이 필요할 수 있습니다. 이런 문제는 사이트마다 문제 발생 여부나 해결방법이 다를 수 있으므로 자세히 설명하지 않겠습니다. 고기문서 1월 26일에서 좀 더 자세히 설명했습니다.
크롤러를 개발 중 예상대로 작동하지 않는다면 스터디 채팅방에서 질문해주세요.
# 상품 url 수집
cards = driver.find_elements(By.CSS_SELECTOR, '.card a')
products += [{'url': card.get_attribute('href')} for card in cards]상품 url을 얻어봅시다. CSS 셀렉터를 사용하여 .card a를 선택합니다. card 클래스들의 자손 중 a 태그를 선택한다는 의미입니다. find_elements()는 주어진 CSS 선택자로 선택되는 여러 엘리먼트들을 찾아줍니다. By.CSS_SELECTOR를 사용하여 CSS selector를 사용한다는 것을 알려줍니다. CSS 말고 XPath 같은 기술을 사용할 수도 있지만 이 문서에서는 설명하지 않겠습니다.
이렇게 얻은 cards를 for 문으로 순회하며 get_attribute('href') 호출로 a 태그의 href의 속성 값을 얻습니다.
여기서 얻은 url을 dictionary에 담아 products에 추가하면서 다음과 같은 데이터를 얻게됩니다.
# products =
[
{'url': '/pycrwlr/1'},
{'url': '/pycrwlr/2'},
{'url': '/pycrwlr/3'},
(...나머지 상품 url...)
]앞서 설명한 최종 products의 데이터에서 url만 채워진 상태의 products가 완성됩니다.
# 페이지 출력
print(f'{page} 페이지')
page += 1이 코드는 단순히 콘솔창에 몇 페이지까지 크롤링 중인지 출력합니다. 위 예제 이미지 중 검정 배경의 콘솔창에 1 페이지, 2페이지가 출력된 예를 확인하실 수 있는데 이 코드로 해당 부분이 출력됐습니다.
# 다음 페이지 이동
el_nexts = driver.find_elements(By.CSS_SELECTOR, 'a[rel=next]')
if len(el_nexts) == 0: break
el_nexts[0].click()위 코드는 다음 페이지 링크가 존재하는지를 찾고 존재하면 클릭, 존재하지 않으면 break하여 while 반복문을 종료합니다.
a[rel=next]는 앞서 설명드리지 못한 CSS 셀렉터입니다. 이는 a 태그 중 rel 속성 값이 next인 요소를 찾는 선택자입니다. <a ref="next" ...>...</a> 이런 형태의 태그가 선택됩니다.
예제 페이지에서 a[rel=next] 태그는 하나만 존재하거나 존재하지 않거나 둘 중 하나였습니다. find_elements의 실행결과는 list이기 때문에 len(list) 호출로 list 아이템의 개수를 구할 수 있습니다. 이 수가 0이면 while을 종료하고 아니라면 list의 첫번째 아이템(다음 페이지 링크의 엘리먼트)을 얻어서 click()합니다.
상품상세 수집
앞서 while문에서 모든 상품의 url을 얻었으니 이제는 각 url의 페이지를 방문하여 상세정보를 얻을 차례입니다.
for product in products:
# 상세 페이지 이동
# 상품명
# 가격
# 섬네일 url
# 상세페이지 html
driver.close()URL만 수집된 products를 순회화며 상세페이지를 얻는 작업을 수행하고 완료되면 close()를 호출하여 드라이버를 종료시킵니다.
# 상세 페이지 이동
driver.get(product['url'])product의 url을 얻어 해당 주소로 크롤러를 이동시킵니다.
# 상품명
product_name = driver.find_element(By.CSS_SELECTOR, 'h2').text
product['name'] = product_name앞서 사용한 find_elements와 달리 끝에 s가 빠진 find_element를 호출합니다. 복수형이 아닌 단수형의 이름에서 return 값이 엘리먼트의 list가 아닌 엘리먼트 하나만 얻는 기능이라는 것을 유추할 수 있습니다. (초보분들 주의: driver 안에 find_elements와 find_element가 둘 다 구현되어 있는 것이지 끝에 s를 넣고 빼고에 따라 알아서 작동하는 것은 아닙니다.)
얻어진 엘리먼트에서 .text를 사용하면 해당 엘리먼트의 text 콘텐츠를 얻을 수 있습니다. product_name = driver.find_element(By.CSS_SELECTOR, 'h2').text 코드는 다음처럼 풀어서 쓸 수도 있습니다.
element = driver.find_element(By.CSS_SELECTOR, 'h2')
product_name = element.text
예제의 코드는 함수 실행 결과를 변수에 담지 않고 바로 .text를 호출하여 한 줄에 작성한 것입니다.
상품명을 얻어서 product dictionary에 name 값으로 상품명을 넣습니다.
# 가격
s_price = driver.find_element(By.CSS_SELECTOR, '.list-group strong').text
s_price = s_price.replace(',', '')
product['price'] = int(s_price).list-group strong 셀렉터의 text를 얻어 가격 문자열을 얻습니다. 문자열을 숫자로 바꾸기 위해 replace() 호출로 문자열의 콤마를 제거하고 int()로 정수 값으로 만들어 product dictionary에 price라는 이름으로 저장합니다.
# 섬네일 url
product['thumbnail'] = driver \
.find_element(By.CSS_SELECTOR, '.details img') \
.get_attribute('src').details img 셀렉터의 엘리먼트를 얻어 src 속성 값을 thumbnail로 저장합니다. 위 코드는 다음 코드와 마찬가지입니다.
# 섬네일 url
product['thumbnail'] = driver.find_element(By.CSS_SELECTOR, '.details img').get_attribute('src')Python에서 이러한 메소드 체인을 여러 줄에 걸쳐서 작성하고 싶으면 줄바꿈 하려는 곳에 \를 붙이고 다음 줄에 이어서 작성합니다.
# 상세페이지 html
product['details'] = driver \
.find_element(By.CSS_SELECTOR, '.details') \
.get_attribute('innerHTML') \
.strip()상세페이지 html을 얻어 details에 저장합니다. 선택 엘리먼트의 텍스트가 아닌 하위 html을 얻으려면 선택 엘리먼트의 .get_attribute('innerHTML')를 호출합니다.
문자열의 앞 뒤로 빈 문자열이 있다면 이를 제거하기 위해 strip()도 호출합니다.
결론
위 과정을 거치면 products 변수에는 크롤링 사이트의 모든 상품 데이터가 저장됩니다.
이 프로그램을 확장하여 products를 파일로 저장했다가 다음번 크롤링 때 새롭게 얻은 products와 비교하여 품절이 되거나 가격이 바뀐 상품을 찾을 수 있습니다.
products를 파일이 아닌 이셀러스나 플레이오토 같은 업로드 솔루션용 엑셀파일로 저장하면 솔루션에서 상품들을 쉽게 마켓에 올릴 수도 있습니다.
더 많은 업무 자동화의 가능성이 남아있습니다. 파이썬이 여러분의 업무을 편하게 만드는 데 도움이 되기를 바랍니다.
감사합니다.